87 KiB
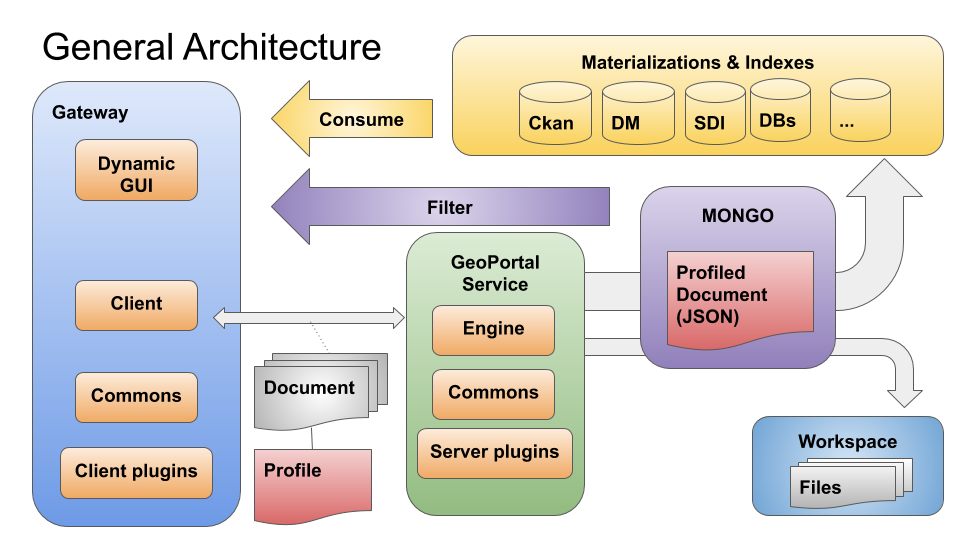
gCube CMS¶
gCube CMS is a software application that allows users to collaborate in the creation, editing, and production of complex digital components called Projects.
The application is built on top of gCube Infrastructure features, for maximum integration with Virtual Research Environments (VREs) and supports :
- Complex Data Management : Projects are made of core Metadata, custom Metadata, multiple linked FileSets
- Versioning, Workflows, Access Policies integrated with the Infrastructure User Role Management
- Materializations (e.g. SDI Layer, Image Thumbnail, DBMS)
- Indexing (e.g. GIS Catalogues, Centroids Layer, CKAN catalogue)
- Event Triggering (e.g. Notifications)
The application is comprised of various components, including :
- GUIs to facilitate end users in managing and consuming Projects
- Service implemented the core business logic
- Plugins set of modular logic implementations (both general-purpose and custom-made) aimed at dealing with Projects Lifecycle Phases and Events
Parameters Init¶
Customize this section for different notebook behaviour and initialization.
%run commons.ipynb
Projects¶
Projects are the main entities in gCube CMS. They represent a complex document comprising of its metadata, its datasets, and related information aimed at properly consume them.\ The present section guides through the management of CMS Projects, explaining it's model and all supported operations.
Projects enacapsulate user's JSON Document in a richer format comprising :
- Core Metadata : Metadata information used by the service to manage the project lifecycle
- The Document : A JSON Object compliant to user's defined schema, reporting both
- The actual metadata regarding the managed documents
- Attachments references to payloads and generated materializations
Projects are linked to Use Case Descriptors (UCD), which define how its Document contents are gonna be treated in the system.
More detailed informations can be found at https://gcube.wiki.gcube-system.org/gcube/GeoPortal_Service
NB: In this notebook we are going to use the UCD "basicUCD". If you want to learn more about UCDs, please refer to wiki pages or related notebooks.
NB: User can experiment with different UCDs but they need to be published in the current infrastructure's Context.
Create New¶
Start This tutorial by creating your new Project.
In this section we are going to create a new simple document and inspect the result. You will learn the basic sections of a Project Metadata and their meaning.
It is sufficient to perform a post operation with our document as the body.
The REST base endpoint for managing projects is SERVICE_BASE_ENDPOINT/projects/UCID where:\
- SERVICE_BASE_ENDPOINT should be discovered from the infrastructure's Information System
- UCID is the ID of the Use Case Descriptor to be used with this project
# Edit this section to customize your document
doc={"myTitle":"Some Big Title"}
project= send(method="POST",dest=projects_endpoint,data=json.dumps(doc))
print("Resulting project is ")
print_json(data=project)
Core Metadata Section¶
Registered JSON Documents are wrapped in Projects, which Let's inspect the registered JSON object structure and the most useful information in it.
The field _theDocument represents our document of interest.
NB : Depending on the linked UCD, the returned document might be different from the output.\ This is due to the fact that the UCD is configured to automatically perform some operation at creation time (e.g. "set defaults values")
print_json(data=project["_theDocument"])
ID¶
The field _id is the unique identifier of the project.\ We are gonna use it for all REST operations that involves our project.
print_json(data=project["_id"])
Accounting Information¶
The field _info contains the following accounting information related to the project :
- _creationInfo : user, context and instant of creation
- _lastEditInfo : user, context and instant of last edit operation
- _access : project access policy (can be OPEN, RESTRICTED or EMBARGOED), project license
print_json(data=project["_info"])
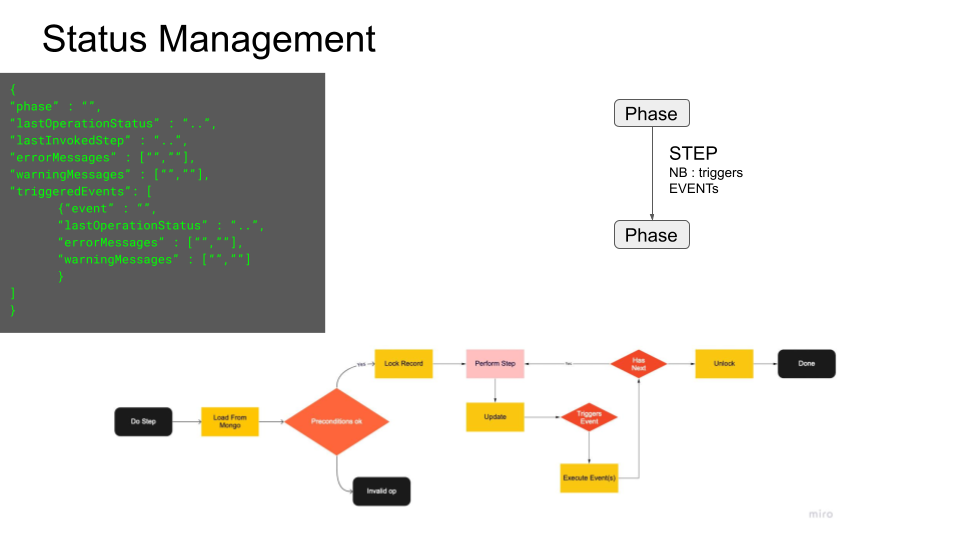
Lifecycle Information¶
The field _lifecycleInformation contains the a structured report of the status of the project containing:
- _phase : The workflow phase in which the document is at the moment
- _lastInvokedStep : Report on the last executed workflow STEP
- _triggeredEvents : Collections of reports regarding the triggered events
- _notes : User defined notes on the status of the project
- _errorMessages : Human readable error messages, if any
- _warningMessages : Human readable warning messages, if any
See Plugins section for more information.
print_json(data=project["_lifecycleInformation"])
Spatial Reference¶
The field _spatialReference contains a GEOJSON geometry identifying the Project.
E.g. like the following :
"_spatialReference":
{
"type": "Point",
"bbox":
[
8.621178639172953,
40.62975046683799,
40.630257904721645,
8.62091913167495
],
"coordinates":
[
-32.00907926554869,
-32.00883133516304
]
}
Temporal Reference¶
TBD
Editing a project¶
Edit the Document section of a Project.
The Document section is the actual document that needs to be managed, and the most basic operation is updating it.\ To do this it's sufficient to perform a put operation with our document as the body, specifying our project's ID
The endpoint for this operation is going to be SERVICE_BASE_ENDPOINT/projects/UCID/ID where:
- SERVICE_BASE_ENDPOINT should be discovered from the infrastructure's Information System
- UCID is the ID of the Use Case Descriptor to be used with this project
- ID is our project Unique Identifier
#We update our document nesting a sub section in it
doc={
"myTitle":"My newer edited title",
"section":{"sectionTitle":"My new SubSection"}
}
# NB uncomment to actually perform edit
project = send(method="PUT",data=json.dumps(doc),dest=projects_endpoint+"/"+str(project["_id"]))
print_json(data=project["_theDocument"])
Upload Attachments : FileSets¶
Projects' documents can contain multiple collections of files called FileSet.
We use the concept of FileSet to identify a collection of files that should be managed together (e.g. GIS shape file along with its SHX file).\ In this section we are going to register a FileSet in our project.\
The operations triggers :
- the upload and archive of passed data streams
- registration of the file in "_theDocument", precisely at the JSON path declared in the request
NB Please beware that FileSet JSON paths MUST be deined in our UCD schema section.
In order to perform this operation we are going to create a JSON object request with at least the following information :
- fieldDefinitionPath : a JSON path pointing to the field definition in UCD schema [NB root is "schema"]
- parentPath : a JSON path pointing to the parent of our target element [NB root is "_theDocument"]
- fieldName : the target element name at which the FileSet is going to be registered
- streams : a collection of JSON objects, each containing
- id : the infrastructure STORAGE volatile ID of our File
- url : [Alternative to ID] the url at which our File can be downloaded.
- filename : our File name
registerFilesetRequest={
"fieldDefinitionPath":"$.section._children[?(@.fileset)]",
"parentPath":"$.section",
"fieldName":"fileset",
"streams":[{"url":"https://www.cnr.it/sites/all/themes/custom/cnr03_theme/img/cnrlogo.svg","filename":"myLogo.svg"}]
}
Once our request is ready we can send it to server with a POST request at SERVICE_BASE_ENDPOINT/projects/UCID/registerFiles/ID where:\
- SERVICE_BASE_ENDPOINT should be discovered from the infrastructure's Information System
- UCID is the ID of the Use Case Descriptor to be used with this project
- ID is our project Unique Identifier
project = send(method="POST",dest=projects_endpoint+"/registerFiles/"+str(project["_id"]),data=json.dumps(registerFilesetRequest))
print("Our Registered FileSet")
print_json(data=project["_theDocument"]["section"]["fileset"])
Workflow operation : Execute STEP¶
Execute operations on a Project in order to manage its lifecycle
Projects lifecycle may involve a lot of operations (usually perfomed by different users), that should be perfomed in a pre defined order eg :
- registration
- approval
- rejection
- validation
- notifications
- processing :
- materialization of Fileset in dedicated engines in order to properyl consume them (e.g. GIS, DBs, Catalogues, Data Analytics..)
- data analytics
We can then visualize our document as passing through different PHASES of it lifecycle (e.g. DRAFT,APPROVED ...). We call STEPs the operations that may later the PHASE of a project by :
- performing a predefined operation on our document
- [optionally]triggering generic events (e.g. notifications)
- altering a Project lifecycle information (reporting outcome, status, messages etc.)
STEPS are implemented in LifecycleManager plugins. The suite comes with a default set of a pre defined, general-purpose plugins that can help manage the user's project. This set can be extended for custom implementations.
NB : Projects lifecycles are configured in linked Use Case Descriptors.\ Each Project starts in Draft PHASE and then changes according to configured Lifecycle Manager.
Once our request is ready we can send it to server with a POST request at SERVICE_BASE_ENDPOINT/projects/UCID/step/ID where:\
- SERVICE_BASE_ENDPOINT should be discovered from the infrastructure's Information System
- UCID is the ID of the Use Case Descriptor to be used with this project
- ID is our project Unique Identifier
Depending on implementations and configurations, invoked STEP may expect/require some additional parameters.\ These can be specified in the request body as a simple JSON object. Please refere to specific plugin documentation for details.
#NB Assuming UCID = "basic"
#Prepare STEP execution request
STEPrequest={"stepID" : "PUBLISH"}
project= send(method="POST",dest=projects_endpoint+"/step/"+str(project["_id"]),data=json.dumps(STEPrequest))
print("Our resulting project new lifecycle information")
print_json(data=project["_lifecycleInformation"])
Materialization¶
Learn how Filesets are materialized into enhanced resources (e.g. GIS Layers, DBMS Tables, Algorithms..)
As discussed above, Fileset may need to be managed in order to :
- materialize them in dedicated engines in order to properyl consume them (e.g. GIS, DBs, Catalogues, Data Analytics..)
- perform data analytics tasks
If these processes generates some kind of consumable resources, they are registered in the Fileset as Materializations
If the above execution went well (check for errors in the displayed lifecycle information), our fileset should have been materialized as a layer in our infrastructure SDI.\ See below the enhanced fileset with new generated information about our new layer.
NB Each FileSet Materialization type has a different structure, in order to adapt to the needs of the application.
print_json(data=project["_theDocument"]["section"]["fileset"])
Gcube SDI Layers¶
GCUBE SDI Layers are materializations of a filesets in a gCube SDI. They expose the following informations, allowing applications and users to consume the generated resources:
- _ogcLinks : Open Geospatial Consortium standard URLs
- _bbox
- _platformInfo : collection of platform - specific JSON objects
Known platform info types are :
- GeoServer
- GeoNetwork (TBD)
- Thredds (TBD)
Here is the layer generated in the above STEP execution
#pipenv install arcgis
# try and visualize GIS
print_json(data=project["_theDocument"]["section"]["fileset"]["materializations"][0])
Accessing Projects¶
The service allows for both access and querying against the internal Document archive.
Querying¶
Queries can be perfomed with a POST HTTP Request at SERVICE_BASE_ENDPOINT/projects/UCID/query with a JSON body with the following fields :
- filter : the JSON filter to apply (see MongoDB documentation for more details)
- projection : the target format to use to represent the returned JSON objects (see MongoDB documentation for more details)
- ordering : determines ordering behaviour -- direction : allowed values are ASCENDING and DESCENDING -- fields : list of fields used for ordering
- paging : determines the paged request's window -- offset -- limit
This feature heavily relies on the underlying Document Store Engine, currently mongoDB.\ Please refer to mongoDB documentation for more details.
The following sections provide some Query example.
#Query All
queryAll = {}
# Query All with PHASE = PUBLISHED
queryPublished = {
"filter" : {"_lifecycleInformation._phase": {"$eq" : "PUBLISHED"}}
}
#ADD Ordering
queryOrdering = {
"filter" : {"_lifecycleInformation._phase": {"$eq" : "PUBLISHED"}},
"ordering" :{"direction":"ASCENDING","fields":[{"_theDocument.title"}]}
}
#GET ONLY FIRST ELEMENT
queryFirst = {
"filter" : {"_lifecycleInformation._phase": {"$eq" : "PUBLISHED"}},
"ordering" :{"direction":"ASCENDING","fields":[{"_theDocument.title"}]},
"paging" : {"offset":0,"limit":1}
}
#GET ONLY TITLE AND AUTHOR
queryTitleAndAuthor = {
"filter" : {"_lifecycleInformation._phase": {"$eq" : "PUBLISHED"}},
"ordering" :{"direction":"ASCENDING","fields":[{"_theDocument.title"}]},
"paging" : {"offset":0,"limit":1},
"projection" :{"_theDocument.title":1,"_info.creationUser.username":1}
}
#Actually performing query
found = send(dest=projects_endpoint+"/query",data=json.dumps(queryAll),method="POST")
print("Result Count :"+str(len(found)))
Get By ID¶
As standard REST agreement, Projects can be obtained by their ID with a POST HTTP Request at SERVICE_BASE_ENDPOINT/projects/UCID/ID
#Lets take an id from previous query
projectId=found[0]["_id"]
project = send(method="GET",dest=projects_endpoint+projectId)
print_json(data=project)
Runtime Configuration¶
Learn about how the service exposes information on how to access and consume generated resources.
As a collateral effect of workflow management, the following resources may be generated at runtime and managed by the service :
- Uploaded file archive : Based on gCube Workspace
- Document archive : Document store based archive of Projects
- Indexes : GIS, Textual, Documental indexes, DBMS
These resources are not linked to one particular Project, but are related to the management of a specific UCD.\ Applications that need to access these resources (e.g. GUIs) can access a Configuration report at SERVICE_BASE_ENDPOINT/projects/UCID/configuration.
print_json(data=send(dest=projects_endpoint+"/configuration",method="GET"))
Use Case Descriptors - UCD¶
Use Case Descriptors (UCDs) are JSON documents containing the configuration settings needed for the management of our Projects, from the creation to their consumption.
In this section we are going to inspect both generic configurations (e.g. Data Access Policies) and some common Plugin configuration (e.g. Lifecycle Management)
# loads UCD from service
queryUCDByID = {"filter" : {"_id":{"$eq":ucid}}}
UCD = send(method="POST",data=json.dumps(queryUCDByID),dest=ucd_endpoint+"query")
print_json(data=UCD)
UCD Format¶
UCD content can be expanded in order to satisfy involved components needs, but its basic structure is fixed.
UCD most notable fields are :
- _id : the Unique Identifier of the UCD
- _schema : the schema of the document to be handled in Projects (see "_theDocument") linked to this UCD
- _creationInfo : accounting information about author, time of creation, Infrastructure Context
- _dataAccessPolicies : access rules based on user Role
- _handlers : specific configurations for all involved components (both Plugins and GUIs)
print_json(data=UCD)
Schema¶
This section represents the expected structure of a managed Document inside a Project linked to the present UCD.
In general it's an optional section of a UCD, but most Handlers and features (e.g. FileSet operations) rely on this section.
It is represented as a map of extensible Field objects with at least the following information :
- _type : String
- _max : Integer Maximum cardinality : (Default is 1)
- _min : Integer Minimum cardinality : (Default is 0)
- _label : String Human Readable Label
- _children : Field Collection Nested fields definition
print_json(data=UCD["_schema"])
Data Access Policies¶
Data Access Policies determine both READ and WRITE authorization on Projects, based on the user's Role
Section _dataAccessPolicies of UCD contains a list of Rules in the following format :
- _policy [Mandatory] : contains read and write operation policy for the present Rule (allowed values are any,own and none)
- _roles [Mandatory] : Collections of users roles for witch the present Rule should be applied
- _enforcer : Additional conditions that should be always applied when accessing data (allowed value is filter)
E.g. The following rule :
- Applies as default (no roles are specified)
- Denies any WRITE operation
- Allows read operations to any Project
- Filters any access to Projects selecting only the one which Phase is Published
{"_policy" : {"_read" : "any", "_write" : "none"}, "_roles":[],
"_enforcer": {"_filter" : {"_lifecycleInformation._phase" : {"$eq" : "Published"}}}},
print_json(data=UCD["_dataAccessPolicies"])
Handlers Configuration¶
Handler configurations are simple JSON objects that wrap specific configuration for sw components that are going to consume our Projects.
Its default structure is :
- _id : identifies the target plugin
- _type : declares the target plugin type
- _configuration : defines the actual plugin configuration (plugin specific)
Please refere to the specific plugin guide for more information
Access and Querying¶
UCDs are also cached in the underlying document store Database, allwoing for the same querying capabilities as for Projects.
UCDs can be accessed by their cached MongoID at the following endpoint : SERVICE_BASE_ENDPOINT/ucd/MongoID
#Perform get UCD by ID
print_json(data=send(method="GET",dest=ucd_endpoint+str(UCD["_mongoId"])))
However, applications might want to perform one of the following queries or a more specific one.\ Check Accessing Projects section for more details.
#Query BY UCID
query = {"filter" : {"_id":{"$eq":ucid}}}
#Actually perform query
print(send(method="POST",data=query,dest=ucd_endpoint+"query"))
Plugins¶
The CMS service itself only deals with generic logic of Projects lifecycle management. The actual hard work is performed by the Plugins configured in the linked Use Case Descriptor.
In more details, the the basic service logic relies on a Lifecycle Manager for the execution of STEPS and EVENT handling, which in turn may exploit other plugins for its purposes.\ Projects and document are only actually updated by the service logic, granting full centralized error management.
In this section we are going to introduce some of the most common plugins that can be configured in UCDs.\ NB : Plugin set can be expanded by the community both from scratch and by extending the already implemented behaviour
Lifecycle Managers¶
Lifecycle Managers are the main responsible for the execution of a Project workflow.
They define the support for STEPs, EVENTs and the resulting document PHASE, so basically they define the Workflow itself.
However customizable, workflows shares some basic behaviour :
- Each Project starts in DRAFT PHASE, then it evolves depending on the configured Lifecycle Manager.
- The following EVENTS are always triggered (even if they can be implemented as NO-OP) :
- ON INIT
- ON UPDATE
- ON DELETE
- ON DELETE FILESET
NB : ROLE based access to STEPs is entrusted to Lifecycle Managers. Provided implementations exploit the feature BasicRoleManager documented below.
The service is distributed with some default implementations in order to provide support for common situations.
DEFAULT-SINGLE-STEP¶
DEFAULT-SINGLE-STEP Lifecycle Manager is a simple workflow implementation consisting of a single STEP "Publish".
PUBLISH step:
- materializes GIS Resources exploiting SDI-Default-Materializer plugin
- indexes GIS resources in a centroid layers exploiting </strong>SDI-Indexer-Plugin</strong> plugin
- sets the Project PHASE to "PUBLISHED"
- [optionally] sends notifications via </strong>Notification</strong> plugin
The following events are also managed :
- ON INIT (basic validation, basic default values evaluation)
- ON UPDATE (basic validation, basic default values evaluation)
- ON DELETE (delete all materializations and index references)
- ON DELETE FILESET (delete Fileset materializations and update index references)
It exploits the feature BasicRoleManager documented below.
DEFAULT-3PHASE¶
DEFAULT-3PHASE Lifecycle Manager is a moderated workflow implementation which allows for approval a rejection of submitted Drafts.
It can be summarized with the following diagram :

It is built on top of DEFAULT-SINGLE-STEP, extending its behavior in order to :
- Manage different indexes (restricted and public) for documets in PHASES "Awaiting Approval" and "Published"
- Allow for iterative editing cycle between submitting user and moderators
It exploits the feature BasicRoleManager documented below.
Basic Role Manager¶
Basic role manager is an internal feature of the CMS service. It restricts execution of STEPs based on user Role. It reads the Lifecycle manager configuration expecting a collection of rules like in the following example.
The following configuration allows users with Editor role to only SUBMIT projects, while Moderator and DataAdmin can also PUBLISH
{
"_id" : "DEFAULT-SINGLE-STEP",
"_type" : "LifecycleManagement",
"_configuration" : {
...
"step_access" : [
{"STEP" : "PUBLISH", "roles" :[ "Moderator","DataAdmin"]},
{"STEP" : "SUBMIT", "roles" :[ "Editor","Moderator","DataAdmin"]}
]
}
}
Indexer Plugins¶
Indexer plugins are in charge of managing resources (Indexes)that contain references to the Projects in order to provide some kind of browsing experience through them.\ They use the information on the selected Project to manage Index entries and (optionally) generate spatialReferences and temporalReferences.
SDI-Indexer-Plugin¶
This plugin manages centroids layers in the SDI GeoServer, generating the Project spatialReference.
It expects following UCD Handler Configuration :
- bboxEvaluation Collection of JSONPaths to use in order to evaluate the Project centroid
- explicitFieldMapping Collection of JSON Object defining the centroid record fields along with JSONPath for their evaluation
- additionalLayers Collection of JSON Objects defining additional layers to use for cross-reference querying of the centroid layers
A typycal configuration might be as following :
{
"_id" : "SDI-Indexer-Plugin",
"_type" : "Indexer",
"_configuration" : {
"bboxEvaluation" : ["$.._bbox"],
"explicitFieldMapping" : [
{"name" : "titolo", "path" : "$._theDocument.title", "type" : "TEXT"}
],
"jslt" : {},
"additionalLayers" : [
{"source" : {"url" : "..."},"toSetTitle":""}
]
}
}
It also expects the Lifecycle manager to provide the following call Parameters :
- Indexing request
- indexName : must be unique (table in postgis)
- worksapce : GeoServer Workspace
- centroidRecord : optionally declare the record to index instead of evaluating it
Materializer Plugins¶
Materializer plugins are in charge of generating resources representing FileSets, and producing their references to be set in the Document itself.
SDI-Indexer-Plugin¶
This plugin orchestrate the creation and publication of GIS Layers in the infrastructure's SDI, registering FileSets in its specific target engine (depending on data formats).
Currently supported data formats are :
- SHP : shape files (along with SHX files if present)
It expects the following UCD Handler Configuration :
- registeredFileSetPaths Collection of JSONPaths pairs pointing to the FileSets to be Materialized by this plugin.
A typycal configuration might be as following :
{
"_id" : "SDI-Default-Materializer",
"_type" : "Materializer",
"_configuration" : {
"registeredFileSetPaths" : [
{"schemaField" : "pianteFineScavo","documentPath" : "pianteFineScavo[*].fileset"},
{"schemaField" : "posizionamentoScavo","documentPath" : "posizionamentoScavo.fileset"}
]
}
}
Getting installed plugins¶
The service allows for inspaction and management of installed plugins.
Installed plugins descriptors can be obtained at SERVICE_BASE_ENDPOINT/plugins and SERVICE_BASE_ENDPOINT/plugins/pluginID
print_json(data=send(method="GET",dest=plugins_endpoint))