4.7 KiB
Introduction
About
CCP is the D4Science Cloud Computing Platform built upon the experience of the previous Dataminer initiative <https://en.wikipedia.org/wiki/D4Science> and uses a novel approach based on containerization, REST APIs and Json.
Several fields of ICT have experienced a major evolution during the last decade and many new advances, such as the widespread adoption of microservice development patterns. This resulted in substantial improvements in terms of interoperability and composability of software artefacts. The vast landscape of new opportunities, in addition to the greatly increased requirements and expectations, have been the drivers for the design and development of a new Cloud Computing Platform that represents the result of a global rethink of the Data Miner.
Architecture
A logical vision of the CCP architecutre is depicted in the following Figure.
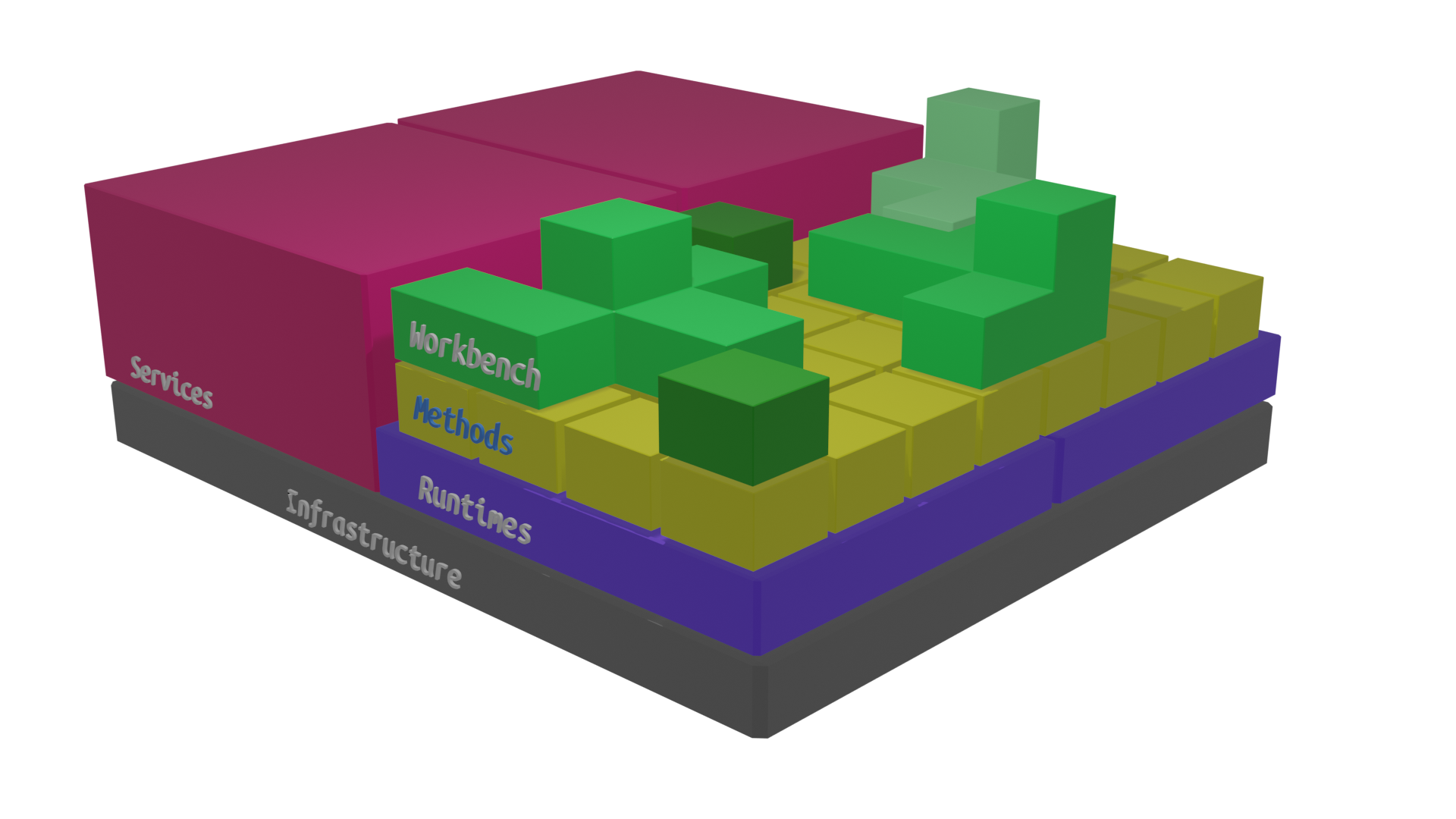
In this vision, CCP is a layered set of components starting at the bottom with the Infrastructure layer, encompassing components such as hardware, Virtual Machines, container based clusters, storage facilities and networks.
The Runtimes layer offers a set of prebuilt, preconfigured execution environments such as containers or Virtual Machine images.
The Method layer contains specification of computational methods that can be anything, from social mining algorithms to AI classifiers and data harvesters. Data scientists with development skills are encouraged to develop new Methods or cloning existing ones, being their responsibility to choose compatible runtimes or propose new ones to be integrated. Tools for sharing the Methods with communities such as Virtual Research Environments are made available at this layer.
The overall user community works at the Workbench layer, which is the abstraction of overarching tools that are able to directly use the available Methods, compose them into workflows and integrate them into visual tools, such as Jupyter Notebook, R scripts, Knime workflows.
Experimentation is the term that defines the activity of configuring new Runtimes, defining new Methods and using them in the Workbench.
In the opposite direction, Consolidation represents the possibility to transform dynamic objects into more static ones in order to improve reusability, portability and overall performance. For instance, workflows or combinations of Methods could be transformed into Methods themselves or even Methods into Runtimes.
The logical architecture presented in Figure 9 shows the natively distributed nature of CCP.
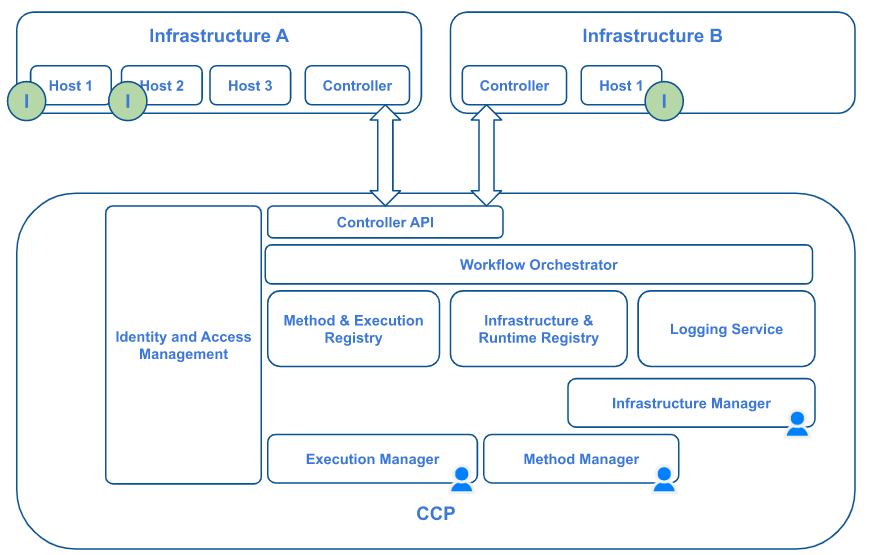
Starting from the top, Infrastructures (as computing resources that will host CCP method executions, i.e. anything from simple laptops up to clusters of server Hosts) can be connected as runtime execution environments by installing a Controller component. Within an infrastructure, Hosts are computational nodes like physical or virtual servers. They are delegated to execute methods.
Controllers are processes that communicate through a specific API with the CCP in order to poll for tasks to perform on the Infrastructure they control. Tasks may include deploying and running methods, cleaning up executions, reporting on the overall status of the Infrastructure.
In order to keep the current state for CCP, a couple of registries are involved. Specifically, the Method & Execution Registry and the Infrastructure and Runtime registry.
User driven visual components are available to manage Infrastructures, Runtimes, Methods and Executions at the frontend. Those components are identified by the user icon in the previous Figure.
Because many of the operations involved are lengthy and asynchronous, CCP includes a Logging Service that is used to send back realtime notifications about the state of a particular process to the user. These notifications include advancement of Executions, advertisement of Infrastructures status updates, and error conditions.
All complex processes involved in CCP are implemented as workflows inside a Workflow Orchestrator which, in addition to granting a high level of flexibility and customisation, allows for a centralised endpoint to monitor progress and check for errors that may occur.
At the basis of all interactions among external actors, such as users and Controllers, a strong authentication and authorisation mechanism is enforced by an Identity and Access Management software (IAM). This enables it to address security requirements as well as to implement ownership attribution and auditing.